
Printing Floating-Point Numbers

This is the first part of a four part series. If you just want to hear about performance and download the code, skip ahead to part four.
Revisions
Mar 05, 2014: Initial version
Aug 17, 2014: Fixed error in returned string length when a negative sign is prefixed onto the number
Aug 09, 2016: Fixed error that could cause a leading zero to be output as a significant digit
causing results like 0.99999999999999995e-007 instead of the correct 9.9999999999999995e-008
History
It wasn't even until the 1970's that anyone really pushed for a proper solution to the problem. In the early days of computers, you couldn't depend on a number's text representation rounding to the correct digit or being accurate enough to read it back in and get the same result. In 1971, Jon White set out to solve the problem once and for all. In '72 he was joined by Guy Steele on his quest. They were at MIT and iterating on their conversion routine as part of the PRINT function in MacLisp. Around 1980, Steele decided that they had something worth writing about and began a paper describing the algorithm, Dragon2. The paper didn't get officially published but it did seem to drift about the internet-less world to the point that it was referenced in a book. It wasn't until 1990 that a final draft of the paper was actually presented. It described the fourth iteration of the algorithm, aptly named Dragon4, which we are about to implement.
As a quick aside, I think code lineage can be a bit fascinating and I got a kick out of how the obscure (and delightfully nerdy) naming of the Dragon algorithm has influenced future work. Steele initially chose the name in reference to the space-filling dragon curve. If you make the curve by folding a strip of paper, you create a sequence of folds and peaks. These are sometimes abbreviated in a sequence of F's and P's which is a bit reminiscent of "floating-point" and thus the name Dragon was chosen. Coincidentally, at the same 1990 conference that Steele presented his paper converting floating-points numbers to text, William Clinger presented a paper on the accurate conversion from text to floating-point numbers. Having known about the Dragon algorithm, he decided to name it's undoing Bellerophon in reference to the monster slayer from Greek mythology (which was close enough to a dragon slayer for Clinger). Arguably, only three improvements have been made to Dragon4 over the past 20 years, and the most recent was substantial enough to require a new name. Florian Loitsch found a way speed up 99.4 percent of all 64-bit floating point numbers by only using small-integer arithmetic, while the remaining 0.6% still need to use a variant of Dragon4. Keeping with tradition, the new algorithm was named after a little dragon, Grisu, that starred in an Italian animated television series.
References
If you're interested in more details on the subject, these are the primary set of papers.
- How to Print Floating-Point Numbers Accurately by Steele and White in 1990
- The link actually points to a retrospective on the original paper from 2003 followed by the original 1990 document.
- Correctly Rounded Binary-Decimal and Decimal-Binary Conversions by Gay in 1990
- Printing Floating-Point Numbers Quickly and Accurately by Burger and Dybvig in 1996
- Printing Floating-Point Numbers Quickly and Accurately with Integers by Loitsch in 2010
If you're okay with using code with a less permissive license, these are the correct implementations I've been able to find.
- dtoa.c
- Written by David Gay (author of one of the above papers), this seems to be the accepted safe implementation. It has been iterated on since 1991 and is used in everything from Python to MySQL to the Nintendo Wii.
- double-conversion
- This is an implementation of the Grisu algorithm mentioned above and is maintained by the author of the paper. It was written for the V8 JavaScript engine in Google Chrome. I think it is also used by Firefox among other large projects.
If you've found your way here, you might also enjoy these two sites.
- Random ASCII
- Bruce Dawson's blog contains a ton of floating-point related articles that are easy reads.
- Exploring Binary
- Rick Regan's blog is almost entirely floating-point related articles and he often dissects conversion implementations finding all sorts of bugs.
The Basics
Before diving into the actual algorithm, let's take a look at a simple (and inaccurate) method for converting a positive floating-point number from binary to decimal. If floating-point numbers could store infinite precision, this algorithm would actually work as is. Given that they don't, this is just an exercise to learn the high level flow used by Dragon4.
A decimal number can be presented as a series of digits and powers of ten. For example, the number \(123.456\) is equal to \(1 \cdot 10^2 + 2 \cdot 10^1 + 3 \cdot 10^0 + 4 \cdot 10^{-1} + 5 \cdot 10^{-2} + 6 \cdot 10^{-3}\). We output the sequence of digits along with the power of the first digit. In this case, we would output the sequence 123456 along with the power 2. The calling function can then format the number as it sees fit (e.g. 123.456 or 1.23456e+002). The caller must also support negative numbers by printing a minus sign and passing the positive version of the number into our algorithm.
const int c_maxDigits = 256;
// input binary floating-point number to convert from
double value = 122.5; // the number to convert
// output decimal representation to convert to
char decimalDigits[c_maxDigits]; // buffer to put the decimal representation in
int numDigits = 0; // this will be set to the number of digits in the buffer
int firstDigitExponent = 0; // this will be set to the the base 10 exponent of the first
// digit in the buffer
// Compute the first digit's exponent in the equation digit*10^exponent
// (e.g. 122.5 would compute a 2 because its first digit is in the hundreds place)
firstDigitExponent = (int)floor( log10(value) );
// Scale the input value such that the first digit is in the ones place
// (e.g. 122.5 would become 1.225).
value = value / pow(10, firstDigitExponent);
// while there is a non-zero value to print and we have room in the buffer
while (value > 0.0 && numDigits < c_maxDigits)
{
// Output the current digit.
double digit = floor(value);
decimalDigits[numDigits] = '0' + (char)digit; // convert to an ASCII character
++numDigits;
// Compute the remainder by subtracting the current digit
// (e.g. 1.225 would becom 0.225)
value -= digit;
// Scale the next digit into the ones place.
// (e.g. 0.225 would becom 2.25)
value *= 10.0;
}
So why doesn't this work? The majority of the issues come from the bottom portion of the loop where we subtract and multiply the floating point numbers. As we continue to perform this operation, we are going to compute values that are not accurately representable in floating-point memory. This error will accumulate over time causing us to output incorrect digits.
There are also some desired features which aren't found here.
- Add support for a user specified number of digits (e.g. only print 6 digits after the decimal point).
- If the number is clipped due to the desired output width or buffer overflow, the final digit should be correctly rounded.
- We should be able to print the minimum number of digits (correctly rounded) that uniquely identifies this number from all other representable numbers such that it can be accurately read back in from text.
Integers
To fix the accuracy issues in our naive implementation, we need to start using integers for math. The first step is deconstructing the floating-point input value into its parts. IEEE floating-point numbers are made up of a sign bit, exponent bits and mantissa bits.
| type | sign bits | exponent bits | mantissa bits |
| 32-bit float | 1 | 8 | 23 |
| 64-bit double | 1 | 11 | 52 |
Once again, the algorithm is only going to support positive numbers so we are not concerned with the sign bit. That leaves the exponent and mantissa portions which are integer based. This brings us one step closer to an integer based algorithm, but before we can write it, we must understand how they are interpreted.
There are four types of floating-point numbers that can be described by the exponent and mantissa.
| exponent | mantissa | usage | |||||
| Denormalized | zero | any value | Denormalized numbers represent a set of floating point values that are too small to fit in the normalized range. Their real number representations are calculated as \(\Large{\frac {mantissa} { 2^{numMantissaBits} } \cdot 2 ^ { 1 + 1 - 2^{numExponentBits-1}} }\).
| ||||
| Normalized | greater than zero and less than the maximum value | any value | Normalized numbers represent the majority of floating point values. Their real number representations are calculated as \(\Large{(1 + \frac {mantissa} {2^{numMantissaBits}}) \cdot 2 ^ {exponent + 1 - 2^{numExponentBits-1}}}\).
| ||||
| Infinity | maximum value (0xFF for 32-bit floats or 0x7FF for 64-bit doubles) | zero | Infinities result from operations such as dividing by zero. | ||||
| NaN | maximum value (0xFF for 32-bit floats or 0x7FF for 64-bit doubles) | greater than zero | NaN stands for "not a number" and they used when an operation does not equate to a real number such as taking the square root of a negative. |
Our binary to decimal conversion algorithm is only going to generate decimal digits for normalized and denormalized numbers. Similar to the sign bit, the handling of infinities and NaNs is left up to the caller.
At this point we know how to represent 32-bit and 64-bit positive values as pairs of integers using normalized and denormalized equations. By first manipulating each input equation into a common format, we can share the same algorithm for them all. Let's compute an unsigned integer, valueMantissa, and a signed integer, valueExponent, such that the input value is equal to \((valueMantissa \cdot 2^{valueExponent})\).
| representation | conversion | valueMantissa | valueExponent |
| 32-bit denormalized | The floating point equation is \(value = \Large{\frac{mantissa} {2^{23}} \cdot 2 ^ {1-127}}\) Factor a \(2^{23}\) out of the exponent and cancel out the denominator \(value = \Large{\frac{mantissa} {2^{23}} \cdot 2^{23} \cdot 2 ^ {1-127-23}}\) \(value = mantissa \cdot 2 ^ {1-127-23}\) | \(mantissa\) | \(-149\) |
| 32-bit normalized | The floating point equation is \(value = \Large{(1 + \frac{mantissa} {2^{23}}) \cdot 2 ^ {exponent-127}}\) Factor a \(2^{23}\) out of the exponent and cancel out the denominator \(value = \Large{(1 + \frac{mantissa} {2^{23}}) \cdot 2^{23} \cdot 2 ^ {exponent-127-23}}\) \(value = (2^{23} + mantissa) \cdot 2 ^ {exponent-127-23}\) | \(2^{23} + mantissa\) | \(exponent - 150\) |
| 64-bit denormalized | The floating point equation is \(value = \Large{ \frac{mantissa} {2^{52}} \cdot 2 ^ {1-1023}}\) Factor a \(2^{52}\) out of the exponent and cancel out the denominator \(value = \Large{\frac{mantissa} {2^{52}} \cdot 2^{52} \cdot 2 ^ {1-1023-52}}\) \(value = mantissa \cdot 2 ^ {1-1023-52}\) | \(mantissa\) | \(-1074\) |
| 64-bit normalized | The floating point equation is \(value = \Large{(1 + \frac{mantissa} {2^{52}}) \cdot 2 ^ {exponent-1023}}\) Factor a \(2^{52}\) out of the exponent and cancel out the denominator \(value = \Large{(1 + \frac{mantissa} {2^{52}}) \cdot 2^{52} \cdot 2 ^ {exponent-1023-52}}\) \(value = (2^{52} + mantissa) \cdot 2 ^ {exponent-1023-52}\) | \(2^{52} + mantissa\) | \(exponent - 1075\) |
Big Integers
We can now represent all floating-point numbers as a pair of integers in the equation \((valueMantissa \cdot 2^{valueExponent})\). We can now rewrite our algorithm with integer math.
Representing a whole number (e.g. 12.0) in an integer is trivial, but things get a little more complex representing a fraction (e.g. 12.3). For fractions, we need to represent the value with two integers: a numerator and a denominator. For example, the number 12.3 can be represented by numerator 123 and denominator 10 because \(12.3 = \large{\frac{123}{10}}\). Using this method, we can write an accurate binary to decimal conversion, but we need to use very large numbers. Neither 32-bit nor 64-bit integers will cut it. We're actually going to need integers with over 1000 bits to deal with some values representable by a 64-bit double.
To handle such large numbers, we'll create a tBigInt structure and write some optimized arithmetic operations for it. Assuming that some version of these existed, we could rewrite our algorithm as follows. I should also mention that we are still coding for readability over performance (things get far more interesting later).
const int c_maxDigits = 256;
// input number to convert from: value = valueMantissa * 2^valueExponent
double value = 122.5; // in memory 0x405EA00000000000
// (sign=0x0, exponent=0x405, mantissa=0xEA00000000000)
uint64_t valueMantissa = 8620171161763840ull;
int32_t valueExponent = -46;
// output decimal representation to convert to
char decimalDigits[c_maxDigits]; // buffer to put the decimal representation in
int numDigits = 0; // this will be set to the number of digits in the buffer
int firstDigitExponent = 0; // this will be set to the the base 10 exponent of the first
// digit in the buffer
// Compute the first digit's exponent in the equation digit*10^exponent
// (e.g. 122.5 would compute a 2 because its first digit is in the hundreds place)
firstDigitExponent = (int)floor( log10(value) );
// We represent value as (valueNumerator / valueDenominator)
tBigInt valueNumerator;
tBigInt valueDenominator;
if (exponent > 0)
{
// value = (mantissa * 2^exponent) / (1)
valueNumerator = BigInt_ShiftLeft(valueMantissa, valueExponent);
valueDenominator = 1;
}
else
{
// value = (mantissa) / (2^(-exponent))
valueNumerator = mantissa;
valueDenominator = BigInt_ShiftLeft(1, -valueExponent);
}
// Scale the input value such that the first digit is in the ones place
// (e.g. 122.5 would become 1.225).
// value = value / pow(10, firstDigitExponent)
if (digitExponent > 0)
{
// The exponent is positive creating a division so we multiply up the denominator.
valueDenominator = BigInt_Multiply( valueDenominator, BigInt_Pow(10,digitExponent) );
}
else if (digitExponent < 0)
{
// The exponent is negative creating a multiplication so we multiply up the numerator.
valueNumerator = BigInt_Multiply( valueNumerator, BigInt_Pow(10,digitExponent) );
}
// while there is a non-zero value to print and we have room in the buffer
while (valueNumerator > 0.0 && numDigits < c_maxDigits)
{
// Output the current digit.
double digit = BigInt_DivideRoundDown(valueNumerator,valueDenominator);
decimalDigits[numDigits] = '0' + (char)digit; // convert to an ASCII charater
++numDigits;
// Compute the remainder by subtracting the current digit
// (e.g. 1.225 would becom 0.225)
valueNumerator = BigInt_Subtract( BigInt_Multiply(digit,valueDenominator) );
// Scale the next digit into the ones place.
// (e.g. 0.225 would becom 2.25)
valueNumerator = BigInt_Multiply(valueNumerator,10);
}
Logarithms
The only remaining floating point operation in our sample is the call to log10() that computes the first digit's exponent. This is another potential source of inaccuracy due to floating-point error. In the original Dragon4 implementation, Steele and White perform a loop of high precision integer multiplications on the numerator or denominator in order to find the accurate exponent. While that is a simple method, it turns out to be rather slow. In the follow-up paper by Burger and Dybvig, two potential optimizations are presented that quickly estimate the exponent within one from correct value. The first method involves calling log10() with a small epsilon to guarantee floor() rounds in the appropriate direction. The second method takes advantage of binary integers and uses a base-2 logarithm to compute the base-10 logarithm. My implementation is based on the second method, but has been tweaked for an additional performance boost.
To compute the exponent of the first digit, we want to solve:
\(firstDigitExponent = \lfloor log_{10} value \rfloor\)
We can rewrite the logarithm in terms of a base-2 logarithm with the change of base formula.
\(log_{10} value = \Large{ \frac { log_{2} value } { log_{2} 10 } } \)
Using the change of base formula one more time, we can prove that
\( log_{2} 10 = \Large{ \frac { log_{10} 10 } { log_{10} 2 } = \frac { 1 } { log_{10} 2 } } \)
Substituting back into our equation for \(log_{10} value\) we can get rid of the division.
\(log_{10} value = log_{2} value \cdot log_{10} 2 \)
We can now update the exponent equation to be
\(firstDigitExponent = \lfloor log_{2} value \cdot log_{10} 2 \rfloor\)
Recall that \(value = valueMantissa \cdot 2^{valueExponent}\). We can compute the base-2 logarithm of value as:
\(log_{2} value = log_{2}(valueMantissa) + valueExponent\)
Because our mantissa is represented as a binary integer, the base-2 logarithm is close to the index of its highest set bit. Explicitly, the highest bit index is:
\( highestMantissaBitIndex = \lfloor log_{2}(valueMantissa) \rfloor \)
Given that \(valueExponent\) is an integer, we can define:
\( \lfloor log_{2} value \rfloor = \lfloor log_{2}(valueMantissa) \rfloor + valueExponent\)
\( \lfloor log_{2} value \rfloor = highestMantissaBitIndex + valueExponent\)
Given that \(highestMantissaBitIndex\) is also an integer, we can write the following inequality.
\( log_{2}(value) - 1 < highestMantissaBitIndex + valueExponent \leq log_{2}(value)\)
Scaling by the positive value \(log_{10} 2\), we get:
\begin{multline}log_{2}(value) \cdot log_{10} 2 - log_{10} 2 \\ < log_{10} 2 \cdot (highestMantissaBitIndex + valueExponent) \\ \leq log_{2}(value) \cdot log_{10} 2\end{multline}
\begin{multline}log_{10}(value) - log_{10} 2 \\ < log_{10} 2 \cdot (highestMantissaBitIndex + valueExponent) \\ \leq log_{10}(value)\end{multline}
Because we are using floating-point numbers, we need to account for drift when we multiply by \(log_{10} 2\). This could put us slightly above our upper bounds so instead we will subtract a small epsilon (e.g. 0.00001) such that:
\begin{multline} log_{10}(value) - log_{10} 2 - epsilon \\ < log_{10} 2 \cdot (highestMantissaBitIndex + valueExponent) - epsilon \\ < log_{10}(value)\end{multline}
Let's now consider the following estimate.
\(log_{10}(value) \approx log_{10} 2 \cdot (highestMantissaBitIndex + valueExponent) - epsilon\)
The inequality implies that our estimate will be within an error of \(log_{10} 2 + epsilon\) below the correct value. Evaluating \(log_{10} 2\) we get approximately 0.301. This works out great because our error is less than one (even with the epsilon added to it) and what we really want to compute is \( \lfloor log_{10}(value) \rfloor \). Thus, taking the floor of our approximation will always evaluate to the correct result or one less than the correct result. This image should help visualize the different cases as the logarithm slides between the neighboring integers and how the error range will overlap the lower integer boundary when the logarithm is low enough.
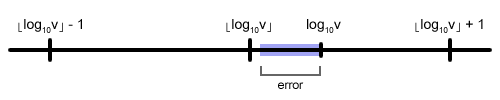
We can detect and account for the incorrect estimate case after we divide our value by \(10^{firstDigitExponent}\). If our resulting numerator is still more than 10 times the denominator, we estimated incorrectly and need to scale up the denominator by 10 and increment our approximated exponent.
When we get to writing the actual Dragon4 algorithm, we'll find that to simplify the number of operations, we actually compute \(1 + \lfloor log_{10} v \rfloor\). To do this we end up taking the ceiling of the approximation instead of the floor. This aligns with the method from the Burger and Dybvig paper. Also, just like in the paper, we are going to do a few less high-precision multiplies when we generate an inaccurate estimate. However, what the paper fails to take advantage of, is computing the estimation such that it tries to be inaccurate more often than accurate. This will let us take the faster code path whenever possible. Right now, our error plus the epsilon is somewhere between 0.301 and 0.302 below the correct value. We then take the ceiling of that approximation so any error below 1.0 produces results that are off by one or correct. As the error approaches 1.0, we will get more results that are off by one. By adding some additional error less than \(1.0 - log_{10} 2 - epsilon\), we can shift our error bounds lower. Explicitly, I subtract 0.69 from the estimate which moves the error range from about (-0.301, 0.0] to about (-0.991, -0.69].
The final inequality is:
\begin{multline}\lfloor log_{10}(value) \rfloor \\ < \lceil log_{10} 2 \cdot (highestMantissaBitIndex + valueExponent) - 0.69 \rceil \\ \leq \lfloor log_{10}(value) \rfloor + 1\)\end{multline}
Minimal Output and Rounding
As it stands, our prototype algorithm will print a number until all precision is exhausted (i.e. when the remainder reaches zero). Because there are discrete deltas between each representable number, we don't need to print that many digits to uniquely identify a number. Thus, we are going to add support for printing the minimal number of digits needed to identify a number from its peers. For example, let's consider the following three adjacent 32-bit floating-point values.
| binary | exact decimal representation | |
| \(\large{v_{-1}}\) | 0x4123c28e | 10.2349987030029296875 |
| \(\large{v_0}\) | 0x4123c28f | 10.23499965667724609375 |
| \(\large{v_1}\) | 0x4123c290 | 10.2350006103515625 |
There is a margin of 0.00000095367431640625 between each of these numbers. For any value, all numbers within the exclusive range \(\large{(value - \frac{margin}{2}, value + \frac{margin}{2})}\) can uniquely identify it. For the above value, \(\large{v_0}\), we can uniquely identify it with the shorter number \(\large{v_{0s}} = 10.235\) because it is closer to \(\large{v_0}\) than it is to to either \(\large{v_{-1}}\) or \(\large{v_1}\).
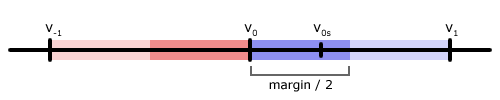
Solving this problem is what lets the Dragon4 algorithm output "pretty" representations of floating point numbers. To do it, we can track the margin as a big integer with the same denominator as the value. Every time we advance to the next digit by multiplying the numerator by 10, we will also multiply the margin by 10. Once the next digit to print can be safely rounded up or down without leaving the bounds of the margin, we are far enough from the neighboring values to print a rounded digit and stop.
In this image, we can see how the algorithm decides to terminate on the shortest decimal representation (the chosen numbers don't correspond to any real world floating-point format and are just for illustration).
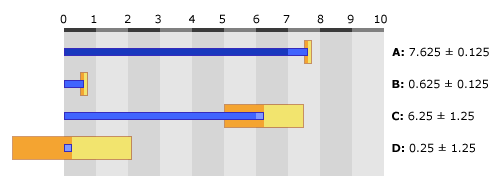
- A: We start off with an input value that has the exact representation 7.625. The margin between each value is 0.25 which means that the set of values within 0.125 units below or above the input value can be safely rounded to it. This plus or minus 0.125 range has been highlighted by the box around the end of the value bar.
- B: We divide our value by 10 to get the first printed digit, 7. We then set the value to the division's remainder: 0.625. The low end of the margin box is greater than zero and the high end is less than one. This means that if we were to stop printing now and round the current digit to 7 or 8, we would print a number closer to another value than it is to 7.625. Because neither the rounded-down or rounded-up digit is contained by our margin box, we continue.
- C: To get our next output digit in the ones place, we multiply our value by 10 giving us 6.25. We also multiply our margin by 10 giving us a distance of 2.5 between numbers. The safe rounding distance of plus or minus half the margin is 1.25.
- D: We divide our value by 10 to get the second printed digit, 6. We then set the value to the division's remainder: 0.25. The low end of the margin box is now less than zero and the high end is greater than one. This means we can safely stop printing and output the current digit as a 6 or 7 because they will both uniquely identify our number. By checking if the remainder of 0.25 is below or above 0.5 we can decide to round down or up (we'll discuss ties shortly). In this case, we round down and the shortest output for 7.625 is "7.6".
Unequal Margins
Unfortunately, the IEEE floating-point format adds an extra wrinkle we need to deal with. As the exponent increases, the margin between adjacent numbers also increases. This is why floating-point values get less accurate as they get farther from zero. For normalized values, every time the mantissa rolls over to zero, the exponent increases by one. When this happens, the higher margin is twice the size of the lower margin and we need to account for this special case when testing the margin bounds in code.
In understanding this better, I find it helpful to make a small floating-point format where we can examine every value. The tables below show every positive floating-point value for a 6-bit format that contains 1 sign bit, 3 exponent bits and 2 mantissa bits.
Positive Denormalized Numbers
\begin{multline}value = \Large{ \frac{mantissa}{2^2} \cdot 2^{1+1-2^{3-1}} \\= \frac{mantissa}{4} \cdot 2^{1-3}}\end{multline}
Here we can see our format's minimal margin of 0.0625 between each number. No smaller delta can be represented.
| binary | exponent | mantissa | equation | exact value | minimal value |
| 0 000 00 | 0 | 0 | (0/4)*2^(-2) | 0 | 0 |
| 0 000 01 | 0 | 1 | (1/4)*2^(-2) | 0.0625 | 0.06 |
| 0 000 10 | 0 | 2 | (2/4)*2^(-2) | 0.125 | 0.1 |
| 0 000 11 | 0 | 3 | (3/4)*2^(-2) | 0.1875 | 0.2 |
Positive Normalized Numbers
\begin{multline}value = \Large{ (1 + \frac{mantissa} {2^2}) \cdot 2^{exponent+1-2^{3-1}} \\= (1 + \frac{mantissa}{4}) \cdot 2^{exponent-3}}\end{multline}
Here we can see our format's lowest exponent has the minimal margin of 0.0625 between each number. Each time the exponent increases, so does our margin by a factor of two and for our largest values the margin is 2.0.
| binary | exponent | mantissa | equation | exact value | minimal value |
| 0 001 00 | 1 | 0 | (1 + 0/4)*2^(-2) | 0.25 | 0.25 |
| 0 001 01 | 1 | 1 | (1 + 1/4)*2^(-2) | 0.3125 | 0.3 |
| 0 001 10 | 1 | 2 | (1 + 2/4)*2^(-2) | 0.375 | 0.4 |
| 0 001 11 | 1 | 3 | (1 + 3/4)*2^(-2) | 0.4375 | 0.44 |
| 0 010 00 | 2 | 0 | (1 + 0/4)*2^(-1) | 0.5 | 0.5 |
| 0 010 01 | 2 | 1 | (1 + 1/4)*2^(-1) | 0.625 | 0.6 |
| 0 010 10 | 2 | 2 | (1 + 2/4)*2^(-1) | 0.75 | 0.8 |
| 0 010 11 | 2 | 3 | (1 + 3/4)*2^(-1) | 0.875 | 0.9 |
| 0 011 00 | 3 | 0 | (1 + 0/4)*2^(0) | 1 | 1 |
| 0 011 01 | 3 | 1 | (1 + 1/4)*2^(0) | 1.25 | 1.2 |
| 0 011 10 | 3 | 2 | (1 + 2/4)*2^(0) | 1.5 | 1.5 |
| 0 011 11 | 3 | 3 | (1 + 3/4)*2^(0) | 1.75 | 1.8 |
| 0 100 00 | 4 | 0 | (1 + 0/4)*2^(1) | 2 | 2 |
| 0 100 01 | 4 | 1 | (1 + 1/4)*2^(1) | 2.5 | 2.5 |
| 0 100 10 | 4 | 2 | (1 + 2/4)*2^(1) | 3 | 3 |
| 0 100 11 | 4 | 3 | (1 + 3/4)*2^(1) | 3.5 | 3.5 |
| 0 101 00 | 5 | 0 | (1 + 0/4)*2^(2) | 4 | 4 |
| 0 101 01 | 5 | 1 | (1 + 1/4)*2^(2) | 5 | 5 |
| 0 101 10 | 5 | 2 | (1 + 2/4)*2^(2) | 6 | 6 |
| 0 101 11 | 5 | 3 | (1 + 3/4)*2^(2) | 7 | 7 |
| 0 110 00 | 6 | 0 | (1 + 0/4)*2^(3) | 8 | 8 |
| 0 110 01 | 6 | 1 | (1 + 1/4)*2^(3) | 10 | 10 |
| 0 110 10 | 6 | 2 | (1 + 2/4)*2^(3) | 12 | 11 |
| 0 110 11 | 6 | 3 | (1 + 3/4)*2^(3) | 14 | 12 |
Positive Infinity
| binary | exponent | mantissa | value |
| 0 111 00 | 7 | 0 | Inf |
Positive NaNs
| binary | exponent | mantissa | value |
| 0 111 01 | 7 | 1 | NaN |
| 0 111 10 | 7 | 2 | NaN |
| 0 111 11 | 7 | 3 | NaN |
As far as I can tell, the original Dragon4 paper by Steele and White actually computes the low margin wrong for the lowest normalized value because it divides it in half. It should actually remain the same because the transition from denormalized to normalized numbers does not change the exponent. This error is not present in the follow-up paper by Burger and Dybvig.
Breaking Ties
When deciding how to round-off the final printed digit, it is possible for the exact value to lie directly between the lower digit and the higher digit. In this case, a rounding rule needs to be decided. You could round towards zero, away from zero, towards negative infinity, etc. In my implementation, I always round to the even digit because it is similar to the rule used by IEEE floating-point operations.
In the reverse algorithm of converting decimal strings into binary floating-point, you can hit a similar case where the string representation lies exactly between to representable numbers. Once again, a rounding rule must be chosen. If you know this rule in both algorithms, there are times when you can print out a unique representation of a number with one less digit. For example, consider how the digit printing algorithm tests if half the high-margin encompasses a digit to round-up to. I tested if the remaining value was greater than one. If we knew how the reverse algorithm would handle ties, we might be able to test greater than or equal to one. David Gay's dtoa implementation seems to do this; therefor it should always be run in conjunction with his strtod implementation.
Personally, I prefer printing extra digits until the rounded number is inclusively contained within the margin. This way the output is guaranteed to uniquely identify the number regardless of the tie breaking algorithm chosen by a strtod parser. Unfortunately, this is only guaranteed for a proper strtod implementation. The implementation that ships with Microsoft Visual C++ 2010 Express sometimes has an off-by-one error when rounding to the closest value. For example, the input "6.439804741657803e-031" should output the 64-bit double 0x39AA1F79C0000000, but instead outputs 0x39AA1F79BFFFFFFF. I can't say for certain where Microsoft's bug comes from, but I can say that the problem of reading a decimal string is more difficult than printing a decimal string so it's more likely to have bugs. Hopefully I can find the time to try my hands at it in the near future.
Coding Dragon4
Next, we will program an optimized implementation of the Dragon4 algorithm. Click here to read part 2..
Comments